다양한 상황에서, 데이터를 그룹별로 묶어 각 중앙값을 기준으로 분포한 데이터만을 샘플링하여 분석할 때가 있다.
그럴 땐 median()이란 라이브러리 함수를 사용할 수 있는 다른 여러 분석 툴을 쓰는게 편리하지만, 만약 그런 내장 함수가 없는 SQL에서 데이터 샘플링을 수행하야 한다면 아래와 같은 방법을 쓰면 된다.
SQL은 RDBMS에 따라 사용할 수 있는 function이 다르기 때문에, 아래 방법은 mysql 기준이지만 거의 모든 rdb에서 사용할 수 있는 기본적인 구문만을 사용한 방법이다.
만약 MSSQL과 같이 Percentile_cnt와 within group 같은 함수와 구문을 제공하는 디비라면 아래 링크를 참조해서 더 간단히 쿼리를 작성해 볼 수 있다.
기본적인 Window function만을 사용하여 median 값 구하기
- 데이터 예시
아래와 같이 category, segment별로 그룹핑 가능한 sku_cd(key)들의 price(measure)가 수천만건 된다고 치자.
이중에서 그룹별로 데이터를 샘플링하기 위해 price의 중앙값을 구하여 그 주변에 분포한 sku_cd 몇개 씩만 필터링을 하고자 하는 것이다.
| sku_cd | category | segment | price |
|---|---|---|---|
| tp203 | Tablet | Premium | 5,000 |
| tp445 | Tablet | Best | 4,000 |
| ta645 | Tablet | Mass | 3,000 |
| ... | ... | ... | ... |
| pt203 | Watch | Premium | 3,000 |
| pa335 | Watch | Best | 2,000 |
| pf334 | Watch | Mass | 1,000 |
| ... | ... | ... | ... |
- 데이터 정렬과 번호 매기기로 각 그룹별 중앙값 부터 구하기
중앙값이란 어떤 주어진 값들을 크기의 순서대로 정렬했을 때 가장 중앙에 위치하는 값을 의미한다.
그러므로 우리가 할일은 그룹 별로 데이터를 정렬하여 순서를 매겨 놓고 그 순서가 가운데인 레코드의 값을 selection하면 된다.
정렬하여 매긴 숫자 중에 가운데 숫자가 몇번인지를 알기 위해 cnt를 사용하여 전체 숫자도 구해 놓는다.
그룹별 정렬 및 집계 연산은 over () partition by "dimension" order by "measure" 를 사용하면 되고, 번호를 매기는 것은 row number()를 사용하면 된다.
SELECT
category,
segment,
price,
ROW_NUMBER() OVER(PARTITION BY category, segment ORDER BY price) rn,
COUNT(*) OVER(PARTITION BY category,segment)
FROM my_table
위의 쿼리를 실행하면 아래와 같이 category, segment별로 총 레코드의 갯수와 price를 기준으로 정렬한 로우넘버(rn)를 얻을 수 있다.

여기서 각 그룹별 로우 넘버에서(rn) 중앙에 위치한 넘버를 찾아내기 위해 cnt 값을 활용할 수 있다.
cnt 값을 반으로 나누면 가운데 로우 넘버를 얻을 수 있는데 cnt 값이 홀수인 경우엔 가운데 값이 딱 나오지만 (예. 1,2,3의 가운데 숫자는 2) 짝수는 숫자 두 개 사이의 값이기 때문에 (예. 1,2,3,4의 중앙값은 2와 3의 사이값) 모든 레코드에 대하여 정수 형태의 로우넘버(rn)를 조회하기 위해 아래와 같이 연산을 추가하여 최종적으로 median 값을 가져온다.
SELECT
category,
segment,
avg(price) AS median_val
FROM
(
SELECT
category,
segment,
price,
ROW_NUMBER() OVER(PARTITION BY category, segment ORDER BY price) rn,
COUNT(*) OVER(PARTITION BY category,segment)
FROM my_table
) AS sub
WHERE
rn IN ( FLOOR((cnt + 1) / 2), FLOOR( (cnt + 2) / 2) )
GROUP BY
category,
segment
그럼 아래와 같이 각 그룹별로 중앙값을 얻을 수 있다.
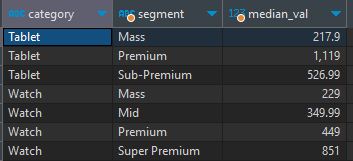
이제 이 그룹별 중앙값을 원본 테이블과 조인하여 ABS(Price-median_val)의 차가 적은 순 대로 정렬하여 원하는 레코드 수만큼만 selection하여 샘플 데이터를 만들 수 있다.
위의 쿼리들을 CTE와 서브쿼리로 이용하여 각각의 스텝에서 만들어 낸 값을 활용한다.
WITH cte AS (
SELECT
category,
segment,
avg(price) AS median_val
FROM
(
SELECT
category,
segment,
price,
ROW_NUMBER() OVER(PARTITION BY category, segment ORDER BY price) rn,
COUNT(*) OVER(PARTITION BY category,segment)
FROM my_table) AS sub
WHERE
rn IN ( FLOOR((cnt + 1) / 2), FLOOR( (cnt + 2) / 2) )
GROUP BY
category,
segment
)
SELECT * FROM (SELECT
sku_cd,
category,
segment,
price,
median_val,
ROW_NUMBER() OVER (PARTITION BY category, segment ORDER BY ABS(price-median_val)) AS row_num
FROM
(
SELECT
m.sku_cd,
m.category,
m.segment,
m.price,
c.median_val
FROM
my_table m
LEFT JOIN cte c ON
m.category = c.category
AND m.segment = c.segment) sub
) sub2
WHERE
row_num <= 30
-- 중앙값을 기준으로 그륩별 30개 레코드 pick
ORDER BY
category,
segment,
row_num;
위의 최종 쿼리를 수행하면 아래와 같이 각 그룹별로 중앙값 주변에 분포된 30개 씩의 레코드가 뽑아진다.
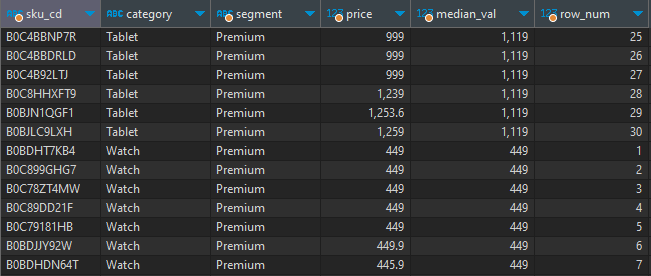
'Work and Study > Data Analytics' 카테고리의 다른 글
| [Docker/R] swap 파일 때문에 wq가 안될때 (0) | 2023.09.06 |
|---|---|
| [Docker/R] Rocker rstudio에서 Rmysql 라이브러리 설치 안될 때 (0) | 2023.09.04 |
| [Docker/R] rocker rstudio로 분석 협업 환경 설정하기 (0) | 2023.09.04 |

